八股文
Spark vs MapReduce:
All are used in big data processing, but Spark uses in-memory while map reduce uses disk-based processing.
For spark, it has other features including lazy evaluation, computations are not executed until like saving or counting is performed. And the data structure in Spark is RDD. Resilient Distributed datasets. These are immutable and can be processed in parallel acroos a cluster. Unlike MapReduce’s linear data flow model. Spark uses DAGs.
For MapReduce, it is a two phase processing; First map and then reduce. At the map phase, proces and transforms the input data into k-v pairs and in the reduce phase, aggregate and combiens output of the map phase to produce results.
So, Spark is faster and ease to use. And mapreduce is reliable for a linear and large-scale data processing tasks.
Mutex vs Semaphore
Mutex is used to provide mutual exclusion, i.e., to ensure that only one thread can access a resource (like a variable or section of code) at a time. Locking Mechanism: When a thread locks a mutex, other threads attempting to lock it are blocked until the mutex is unlocked. Ownership: A mutex has the concept of ownership. Only the thread that has acquired a mutex can release it. Use Case: Ideal for protecting shared data/resources in a scenario where only one thread should access the data at a time.
Semaphores are used to control access to a resource that has a limited number of instances. Counting Mechanism: A semaphore maintains a count, which is decremented by a thread that acquires the semaphore and incremented when a thread releases it.
No Ownership: Unlike mutexes, semaphores don’t have a specific ownership. Any thread can release a semaphore, not necessarily the one that acquired it.
Types: There are binary semaphores (which are similar to mutexes) and counting semaphores (which allow multiple accesses up to a set limit).
Use Case: Useful for limiting access to a resource pool, like database connections.
SQL vs NoSQL
SQL: structured schema with tables, rows and columns. Data is orgranized into well-defined structures. SQL database provide strong consistency, ensuring the data remains in a valid state at all times. ACID transcations are used to maintain data integrity.
NoSQL are non-relational and handle various data formats, like semi-structured and unstructured data. About consistency, it offers various consistency models, including eventual consistency. It use BASE (Basically Available, Soft state, Eventually consistent) semantics instead of ACID.
Cache:
LRU Least Recently Used
FIFO
LFU Least Frequently Used
Malloc Free Realloc Calloc
When call malloc, it requests a block of memory of the specified size from the heap. In a segregated free list with a better-fit algorithm, malloc will search the segregated free lists to find a block that closely matches the requested size (but is slightly larger to avoid fragmentation).
free is used to deallocate memory previously allocated by malloc, realloc, or calloc. When you call free, it marks the corresponding block of memory as free in the segregated free list.
In a better-fit algorithm, free may involve coalescing (merging) adjacent free blocks to prevent memory fragmentation and to maintain the list of free blocks efficiently
realloc is used to resize a previously allocated block of memory. It can be used to make a block of memory larger or smaller. When you call realloc, it may perform one of the following actions:
If the requested size is smaller than the current block’s size, it may split the block, marking part of it as free and returning a pointer to the remaining portion. If the requested size is larger than the current block’s size, it may search for a larger free block in the segregated free list. If found, it may move the data to the new block and return a pointer to it. In a better-fit algorithm, realloc will try to find the best-fit block that minimizes waste and fragmentation.
calloc stands for “contiguous allocation.” It is used to allocate and initialize multiple blocks of memory, typically for arrays or data structures. When call calloc, it allocates a block of memory that can hold a specified number of elements, with each element of a specified size.
First fit / next fit: search linearly starting from some location, and pick the first block that fits.
Next Fit is similar to First Fit but starts searching for free memory from the location where the previous allocation ended. This can help reduce fragmentation compared to First Fit. Best Fit searches for the smallest available block of memory that can accommodate a request. This minimizes waste but can lead to fragmentation and is less efficient than other algorithms.
Segregated free list is to maintain separate lists of free memory blocks, each list containing blocks of a specific size range. This allows the allocator to quickly locate a suitable free block for a requested memory allocation size without searching through all free blocks
Virtual Memory
It extends the available physical RAM (Random Access Memory) by temporarily transferring data from RAM to disk storage.
each process running on a computer system believes it has a complete and dedicated address space that spans from 0 to the maximum address supported by the architecture (e.g., 2^32 addresses in a 32-bit system or 2^64 addresses in a 64-bit system). This illusion is created by the memory management unit (MMU) and the page table. In detail, when a program running on the CPU accesses memory, it uses virtual memory addresses rather than physical addresses. These virtual addresses are translated into physical addresses by the memory management unit (MMU) hardware. For page table, it is is a data structure used by the operating system to map virtual addresses to physical addresses. It keeps track of which pages are currently in RAM and which are stored on disk. It is like as a form of a cache. Page table entries (PTEs) typically store information about the mapping, including whether the page is in RAM (a cache hit in a sense) or needs to be fetched from secondary storage (similar to a cache miss).
Stack vs Heap
The stack is used for static memory allocation, which includes local variables and function calls.
Size and Allocation: The stack has a limited size, and memory is allocated in a last-in, first-out (LIFO) manner.
Speed: Allocation and deallocation on the stack are fast since it involves only moving the stack pointer.
Lifespan: Variables on the stack exist only within the scope of the function that created them.
Automatic Management: The compiler automatically manages the stack.
The heap is used for dynamic memory allocation, where the size and lifetime of variables or objects are not known at compile time.
Size and Allocation: The heap can typically grow dynamically, limited only by the system’s available memory.
Speed: Allocation and deallocation on the heap are slower as they require more complex bookkeeping.
Lifespan: Memory on the heap remains allocated until it’s explicitly freed, often by the programmer.
Manual Management: In languages like C and C++, programmers must manually manage heap memory, leading to complexities like memory leaks and dangling pointers.
Microservices - why not and why
Modularity: Microservices allow for breaking down complex applications into smaller, manageable, and independent units. This modular structure makes it easier to understand, develop, and test the application.
Scalability: Different microservices can be scaled independently, allowing for more efficient resource use. For instance, a component with high demand can be scaled separately without having to scale the entire application.
Flexibility in Technology: Each microservice can potentially be written in a different programming language or use different data storage technologies, depending on what is best suited for its purpose.
Faster Deployment and Time to Market: Since microservices can be deployed independently, new features can be brought to market more quickly and with less risk.
Resilience: A failure in one microservice does not necessarily bring down the whole application, making the application more robust and resilient.
But:
Complexity in Coordination: Microservices introduce challenges in communication and coordination between various services. Managing multiple interdependent services can be more complex than managing a monolithic architecture.
Network Latency: Inter-service communication over the network can introduce latency, which might impact performance.
Data Management Complexity: Maintaining data consistency and integrity across services can be challenging, especially with each microservice managing its own database.
Difficulty in Testing: Testing a microservices-based application can be more complex compared to a monolithic application due to the number of services and their interactions.
Container vs Virtual Machine
They used to create isolated environments for running applications, but they operate differently and serve different purposes in the world of computing.
VM: run on top of physical server and a hypervisor, like VMware. Each VM includes all necessary bunaries and libraries and entire guest OS. So VM is larger.
Container:share the host system’s kernel but package the application and its dependencies (libraries, binaries, etc.) into a container image. Lightweight
They coexist and leveraging the strengths of each technology
RestAPI
RestAPI is a web service implementation that adheres to the REST architectural constraints. And REST is a set of principles that define how Web standards.
RestAPI include: Stateless Communication: Each request from client to server must contain all the information needed to understand and process the request. And it has to have a client-server architecture, it needs to use HTTP methods like GET POST PUT DELETE. It should be defined as cacheable or not, and it uses a layered system. Other alternatives are liek GraphQL which uses multiple endpoints to retrieve different data to perform operations. And gRPC which is especially useful for microservice architecture
Website DNS:
First check the cache in the browser to see if it has a record of the IP address;
If not, it will do a DNS Query, it wil first go to a local DNS cache, and then reach to internet service providers DNS server, if still not get the IP address, the request will be forwarded to higher-level DNS until the IP is found.
Once got the IP, our hardware will use ARP to find the MAC address of the gateway router, And then the browser will start like TCP with, of course, handshaking. SYN, SYN-ACK, ACK; And then sending HTTP, if it is HTTPS, it will do some verification and server gives the response after processing the request with some status code as well as contents like HTML, and then the Browser render the page
Network Layer:
OSI Model: 7 layers: Physical, Data link, network, transport, session, presentation, application;
Physical: transmission and reception of unstructured raw data between a device and a physical transmission medium
DataLink: node-to-node data transfer
Network: Device addressing, routers operate at this layer
Transport: transfer data between hosts
Session: Manage sessions between end-user apps
Presentation: Data encryption
Application: interacts with the software application
TCP/IP:
Link layer, internet layer, transport layer, application layer
Link (physical and data link)
Internet: network
Transport: transport
Application: Session, presentation, application
gRPC
HTTP/2 so, it uses TCP for the transport layer, with protocol buffers at the presentation layer.
Cloud v.s. Cloud Native
“cloud” refers to the computational infrastructure and services available over the internet, “cloud native” refers to a methodology and design philosophy to build and run applications that harness the full potential of cloud computing.
I usually heard SAAS, PAAS, iaaS
FaaS
FaaS, or Function as a Service, is a category of cloud computing services that allows developers to execute and manage individual functions in response to events without the need to manage the infrastructure. This is a subset of serverless computing. It is event driven, like I need to have SQS + SNS + Lamba function to make the SNS trigger the function. It is stateless, short-lived and able to auto scale.
Docker vs K8s
Docker is a platform that allows us to build, ship, and run applications inside containers. Containers encapsulate an application and its dependencies into a single, consistent unit, making it easy to move across different environments.
Kubernetes is a container orchestration platform designed to automate the deployment, scaling, and management of containerized applications.
Docker is about creating and running individual containers.
Kubernetes is about coordinating clusters of containers, ensuring they work in harmony with one another.
Container v.s. Virtual Machine
Containers:
OS-level virtualization.
Lightweight and fast.
Share the host’s OS kernel.
Best for microservices and cloud-native applications.
Virtual Machines:
Hardware-level virtualization.
Heavier, with their own full OS stacks.
Stronger isolation due to separate kernels.
Best for strong isolation needs and varied OS requirements on the same host.
containers can run inside VMs, leveraging the strengths of both technologies.
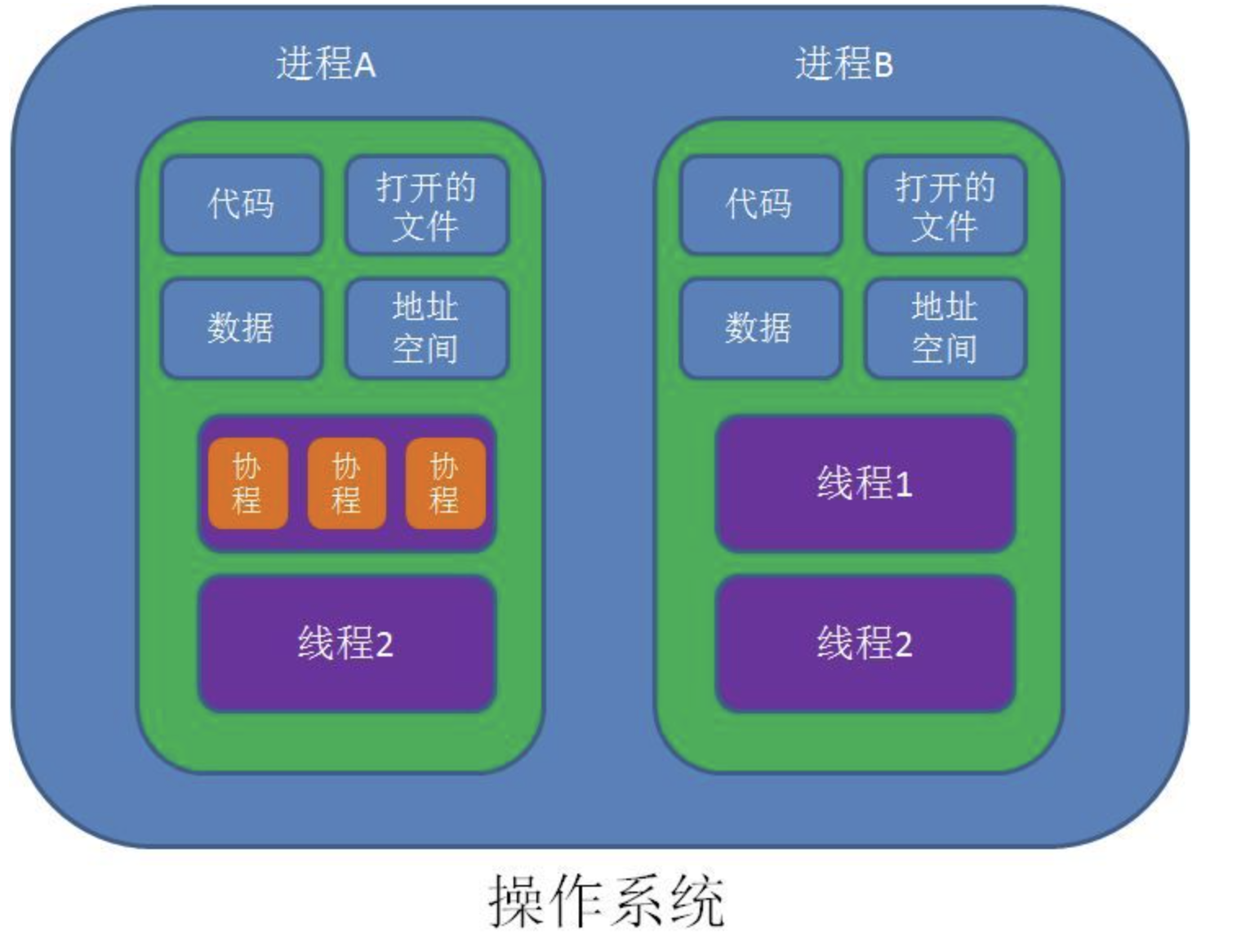
进程 vs 线程 vs 协程
Process contains Thread contains Coroutines
Process between each other are independent, while thread in a process share the memory space, like code, data, stack, and space resources like signals
Thread and Coroutine: Thread needs locks to make the data consistent while coroutine does not, we can simply check the state in the coroutine;
包含关系如下: